
1. 동적 크롤링
동적 크롤링이란 동적 웹 사이트의 데이터를 추출하는 방법으로, 동적 웹 사이트는 url만으로 접근할 수 없는 웹 사이트를 말한다. 즉 데이터를 로딩해 오거나, 특정 정보를 알고 있어야만 접근할 수 있는 웹 사이트는 동적 크롤링을 사용해야한다는 뜻이다.

동적 크롤링에 대한 기본 개념을 알아봤으니 동적 크롤링 예제를 함께 살펴보자.
1-1. 라이브러리 호출
동적 크롤링을 위해 다음과 같은 라이브러리를 가져와야한다.

selenium 라이브러리는 사용자가 직접 제어하지 않아도, 코드에 따라 자동으로 동작할 수 있게 도와준다. ChromeDriverManager 라이브러리는 우리가 사용 중인 크롬의 버전이 최신 버전과 같을 경우 웹 페이지를 열어 작업이 가능하고, 버전이 맞지 않을 시 자동으로 다운로드를 해주는 기능을 지원한다.
마지막으로 selenium.webdriver.chrome.service는 selenium과 크롬 사이의 접근성을 위해 호출된다. 동적 크롤링을 위한 제어 라이브러리는 이것으로 소개를 마치고, 다음으로 호출되는 라이브러리들은 기본적인 크롤링, 데이터 정제를 위한 pandas 등을 호출해주었다.
1-2. 기본 설정

동적 크롤링의 최대 한계점은 각 사이트 별로 비정상적인 접근을 막기 위해 어느 정도 보안이 갖춰져있다는 것이다. 비정상적인 접근임을 감지하게 되면 접속하는 IP를 차단하여 접근하지 못하게 한다. 이 한계점을 어느 정도 극복하기 위해 options 변수를 설정하고, 보안 기능인 샌드박스를 비활성화, dev/shm 디렉토리를 사용하지 못하게 하는 등 조치를 취하게 된다.
샌드박스를 활성화 하지 않는 다는 뜻은 외부로부터 들어온 프로그램이 보호된 영역에서 동작해 시스템이 부정하게 조작되는 것을 막는 보안 형태인 샌드박스를 비활성화 한다는 뜻이다.
그 다음 줄의 disable-dev-shm-usage는 공유 메모리 파일 시스템 크기를 제한하지 않게 설정하는 것이다. 기본적으로 큰 메모리를 사용하게 되면 파일 시스템의 크기가 부족하여 브라우저가 충돌할 수 있다. 크롤링할 데이터의 크기가 혹시나 파일 시스템의 크기를 넘어 충돌하게 되면 프로그램이 종료된다. 비정상 종료를 막기 위해 해당 기능을 잠시 사용 중지하는 것이다.
크롬을 최신 버전으로 맞춰주고, 실제 드라이버를 할당해준다. 또한, 윈도우 크기를 설정해주고, 크롤링하고자 하는 웹 사이트의 url을 불러온다. 로딩이 될 수 있게 시간을 10초간 기다려주고, 스크롤 다운하는 동작을 설정해준다.
1-3. 댓글 크롤링
모든 댓글을 가져오기 위해서는 모든 댓글을 불러와야한다. 그렇기 때문에 더 이상 스크롤이 되지 않는 범위까지 내려가야한다. 다음의 코드를 살펴보자

무한반복을 뜻하는 while True:를 이용해 가장 하단부까지 내려가고, 크롤링을 진행한다. 여기서 html파일을 살펴보게 되면 구글의 경우 독자적인 html태그를 사용하므로 이 점을 유의해야한다. 'yt-attributed-string' 태그의 'content-text'라는 id를 select메서드를 이용해 가져온다. 지난 게시물의 코드와 다른 점은 select 메서드를 사용했다는 점이고, 딕셔너리 형식으로 id인지, class인지 구분하지 않는 다는 것이다.
그럼 어떻게 id와 class를 구분하게 될까?
그 방법은 태그와 css 사이의 기호를 확인하면 된다.
- id: '#' 넘버 사인을 이용하여 태그와 css를 구분하게 된다.
- class: '.' 마침표를 이용하여 태그와 css를 구분하게 된다.
예제의 코드에서는 'yt-attributed-string' 태그의 'content-text' id를 사용하는 것을 알 수 있다. 댓글들을 불러와 comment_list에 저장했으니 데이터프레임으로 옮기는 작업을 해야한다.
1-4. 데이터프레임에 저장

위에서 댓글이 포함된 태그를 가져왔으니 raw데이터를 정제해야한다. 앞뒤태그를 모두 없애고 text만을 남긴다. 다음으로는 개행문자들을 제거하는데 줄바꿈, tab, 앞뒤 공백 들을 삭제해준다, 이렇게 정제된 데이터들을 새로운 리스트에 담고, 이를 딕셔너리화 한 다음 데이터프레임으로 변환해준다.
1-5. 데이터프레임을 csv파일로 저장

데이터프레임이 제대로 생성이 되었는지 info메서드로 확인후 원하는 제목의 csv파일로 저장해준다. 여기서 중요한 점은 한글 데이터가 포함되어 있으므로 필히 인코딩을 설정해주어야 한다는 점이다. 마지막으로 열어놨던 드라이버를 닫아주면 동적 크롤링이 종료된다. 데이터 셋을 만들어 봤으니, 지난 시간에 이어 시각화 하는 방법을 다시 한번 알아보자.
2. 데이터의 시각화

데이터를 시각화하기 위해 위와 같은 라이브러리를 호출해준다. 지난 게시물에서 다루었던 matplotlib.pyplot, koreanize_matplotlib 그래프를 그려주는 라이브러리를 호출해준다. 여기서 각종 자료형을 다루는 numpy라이브러리, 상호작용이 가능한 그래프를 그리기 위한 plotly, 이미지 처리를 위한 PIL, 단어 구름을 위한 wordcloud라이브러리를 호출해준다. 시각화에 왜 numpy가 사용되는지는 나중에 알 수 있게 된다.

데이터 크롤링을 이용하여 추출한 데이터를 read_csv 함수를 이용해 호출하여 데이터프레임에 저장한다.

이제 한글의 형태소들을 추출하기 위해 konlpy 라이브러리를 사용하는데, 이번에 사용하는 모델은 Okt이다. Okt는 트위터에서 제작한 한글 형태소 분석기이다. 그 매개변수로는 댓글들의 내용을 넘겨주게 되는데, 다른 데이터들과의 구분자를 공백으로 지정하고, 문자열임을 지정해준다. 그렇게 하면 출력된 결과와 같이 데이터 프레임이 만들어 진다.

문자열의 길이를 나타내어 새로운 columns, 열에 저장하는 코드이다. count 열에는 문자열의 길이를 나타내는 정수형의 데이터가 저장된다. 각 단어의 길이를 확인했으니 각 단어별 빈도수를 계산하는 다음의 코드를 확인해보자.
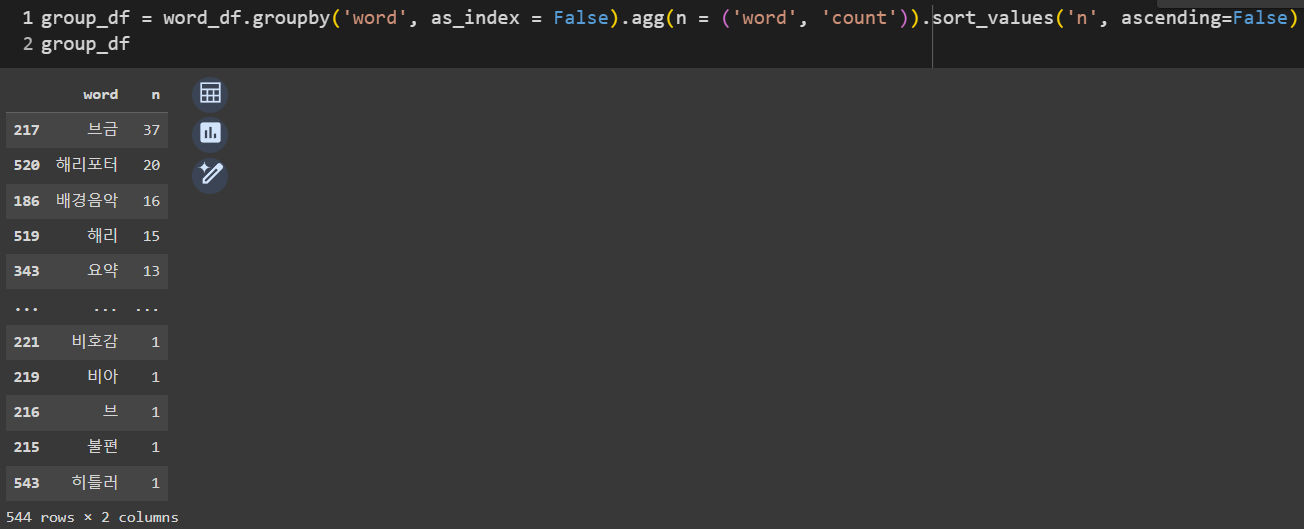
다음은 단어의 빈도를 확인하고, 가장 빈도가 높은 값이 첫 번째로 올 수 있게 내림차순 정렬하게 된다. 체이닝 형식의 코드이기 때문에 여러 기능이 한 줄의 코드로 함축되어 있다. 먼저 groupby로 그룹화를 해주고, agg메서드를 이용하여 연산 함수를 적용해준다. 마지막으로 정렬 함수를 사용하면 단어의 사용 빈도수를 알 수 있게 된다.
빈도를 알게 되었다고 한들, 수치형 데이터로 표시되어 있으면 실감하기 어렵다. 그렇기 때문에 plotly라이브러리의 express 객체를 이용하여 상호작용형 그래프를 그려보았다.

상위 20개의 값들만 그래프로 그리고, x축은 단어를, y축에는 빈도수를 나타내었다.

저번 게시물에서도 그렸듯 wordcloud라이브러리의 WordCloud함수를 이용하여 단어 구름을 만들었다. plt.axis를 off로 설정함으로써 그래프의 격자 무늬를 제거하였고, 그림의 보간을 bilinear로 설정하였다.
해리포터 관련 영상의 댓글들을 크롤링해와 만든 단어 구름인만큼, 이번 단어 구름에는 masking을 적용해볼 것이다. masking은 말 그대로 mask를 씌워 단어들의 배치와 색상을 바꾸는 작업이다.

원하는 이미지를 지정하여 변수에 할당한 후, 해당 이미지를 numpy 배열로 변경한다. 이를 통해 색상이 모두 수치화되며 이를 위해 numpy 라이브러리를 위에서 호출했었다. 모든 색상에는 색상 코드가 있고, 색상에 따라 RGB 값이 다르다. 이 점을 이용하여 이미지의 색상들을 수치화하여 단어 구름에 속하는 단어들의 색상들을 지정해줄 수 있다. 지난 게시물에서는 WordCloud의 메서드로 generate만을 사용하였지만, 이번 게시물에서는 generate_from_frequencies 메서드를 사용하게 된다. mask를 지정해주고, numpy 배열의 색상을 따르게 된다.

위의 코드를 실행했을 때의 결과물이다. 자세히 보면 단어들이 헤리포터라는 글씨대로 위치해있는 것을 알 수 있다.
점차 난이도가 높아지고 있다. 이해하는 데에 할애하는 시간을 늘려야겠다.
포기하지 말고, 최대한 많이 배워가자.
'ABC부트캠프 데이터 탐험가 과정' 카테고리의 다른 글
| [15일차] ABC 부트캠프 이미지 크롤링 및 프로젝트 주제 선정 (0) | 2024.07.24 |
|---|---|
| [14일차] ABC 부트캠프 동적 크롤링을 이용한 노래 가사 분석 (11) | 2024.07.24 |
| [12일차] ABC 부트캠프 ESG Day(데이터로 보는 분야) (2) | 2024.07.20 |
| [11일차] ABC 부트캠프 파이썬을 이용한 데이터 크롤링 1 (2) | 2024.07.18 |
| [10일차] ABC 부트캠프 파이썬 프로젝트(데이터분석) (0) | 2024.07.17 |