
금일 배운 내용은 어제와 크게 다른 바 없다. 하지만 달라진 알고리즘에 대해 분석해보자.
1. 라이브러리 호출 및 동적 크롤링을 위한 기본 설정

해당 사진을 확인해보면 지난 게시물과 크게 다를 것이 없을 것이다. 하지만 다른 점이 있다면 By라는 모듈을 호출한 것이다. By 모듈은 키워드를 전달하게 되면 해당 키워드를 검색할 수 있게 된다. 또한 re라이브러리를 호출함으로써 정규표현식을 사용하여 문자열을 정제할 수 있게 된다. 나머지 라이브러리들과 기본 설정들은 지난 게시물에 모두 설명이 되어 있으니 링크를 참고하자.

지금까지는 2중, 3중 반복문을 이용하여 데이터들을 크롤링 했었다. 하지만 이번에는 크롤링 함수를 선언하여 함수 내부에 기능을 구현해보았다. 함수의 매개변수를 보게 되면 url과 start 변수를 받아오는 것을 알 수 있다. 함수 호출 부에서 url과 start 변수에 해당하는 날짜를 넘겨주게 된다. 노래 제목과 가수 이름을 추출하는 코드를 자세하게 살펴보자.

노래 제목을 가져오는 방법에서 지금까지는 BeautifulSoup 라이브러리의 find_all 함수를 사용하였지만, 이번에는 selenium 라이브러리의 By 모듈과 함께 find_elements를 사용하여 원하는 태그의 클래스를 지정한다.
하지만 find_all 함수와는 다르게 태그를 명시하지 않아도, 클래스 혹은 id를 통해 해당 내용들을 찾을 수 있게 해준다.
제목과 가수들을 추출했다면 리스트 조건 제시법(list comprehension)을 사용하여 리스트화 해준다.
리스트 조건 제시법이란 리스트의 요소를 지정하지 않고, 조건을 제시함으로써 조건에 부합한 요소들로 리스트가 구성되어 있다. title_list와 singer_list의 경우가 리스트 조건 제시법으로 생성한 리스트에 해당한다.

다음으로는 가사를 추출하기 위해 songId를 추출해와야 한다. 주석으로 되어 있는 a태그를 확인해보면 소괄호 안에 위치한 2 번째 숫자가 노래의 아이디이다. songId를 추출하기 위해서는 콤마를 기준으로 앞 뒤로 나누고 1번 인덱스를 선택한다. 그런 다음 re라이브러리의 정규표현식을 이용하여 숫자가 아닌 문자들을 모두 지운다. 그렇게 하면 songId를 제외한 모든 문자열이 삭제되고, songId만 남게 된다. 이렇게 정제된 songId를 리스트에 담게 되는데, 만약 songId가 존재하지 않는 노래는 공백을 리스트에 삽입하게 된다.
노래의 id를 알게 되었으니 가사를 추출해보자.

가사를 추출하기 위해서는 곡 정보 탭에 들어가야한다. 곡 정보 탭에 들어가기 위해 songId를 추출하였고, 곡 정보 탭에 들어가기 위해서는 별도의 클릭이 필요하다. 과정을 자세히 살펴보자.

songId와 url을 포맷팅 방식을 이용하여 합쳐준다. driver을 사용하여 생성된 url을 열어주고, 로딩되는 시간 3초 만큼 기다려준다. 동적 크롤링이 필요한 이유가 여기서도 나타나게 된다. 전체 가사를 확인하기 위해서는 접혀있는 가사를 펼쳐야한다.

다음과 같이 구성되어 있는 화면에서 펼치기 버튼을 누르는 코드는 아래와 같다.

펼치기 버튼에 해당하는 클래스를 찾은 뒤 click메서드를 사용하고, 펼치기 버튼을 클릭하면 전체 가사가 로딩될 때까지 기다려주는 시간을 지정해준다.
전체 가사가 포함된 html을 불러온 다음 파싱하게 되면 아래와 같이 가사를 추출할 수 있다.

하지만 가사 사이사이 <br>태그를 확인할 수 있다. <br>태그는 줄바꿈 태그로 사용되고 있다. 해당 <br>태그를 삭제하게 되면 문장과 문장 사이가 공백 없이 이어지기 때문에 <br>태그 자리에 공백을 넣어주어야 한다.

가사 사이사이에 있는 <br>태그들을 모두 띄어쓰기로 바꾸어주고, 가사 앞 뒤에 위치한 html 태그들을 모두 삭제해준다. 이때 사용되는 방법이 정규 표현식을 이용하여 지정해준다. 전체 html 태그에 대한 정규식은 '<.*?>'으로 표현 가능하다. 정규 표현식을 검사하는 코드를 cleaner에 할당하고, raw 데이터인 lyric을 매개변수로 넘겨주게 된다. 그렇게 되면 cleaner를 거친 lyric은 html 태그들이 제거되어 있는 clean_lyric으로 변환되고, 2개 이상의 공백을 제거해줄 수 있게 다시 한번 sub라는 치환 함수에 넘겨주게 된다. 정제 과정은 끝이 났다. 이제 정제된 가사들을 가사 리스트에 저장하게 되고, 만약 가사가 존재하지 않을 경우 공백을 저장하게 된다.

크롤링 한 데이터를 Dataframe으로 만들어주고, Dataframe을 csv파일로 저장하면 크롤링이 종료된다. 크롤링이 종료되었으니 driver를 종료해주는 과정을 꼭 진행해야 낭비되는 메모리를 최소화할 수 있다.

수집하고자 하는 연도를 start 변수에 담고, url과 합쳐준다. 그렇게 만들어진 url을 지금까지 알아본 함수에 넘겨주고, 수집하고자 하는 연도도 함께 넘겨주면서 호출해주면 제목, 가수, 가사에 대한 데이터들을 추출할 수 있게 된다.
다음으로는 추출한 데이터를 시각화하는 방법에 대한 설명이다.
2. 데이터의 시각화
지금까지는 konlpy 라이브러리의 형태소 분석기를 사용하였지만, 이번에는 문자열을 직접 가공하는 방법을 알아보자.

제일 먼저 크롤링한 데이터를 불러와 가사를 한 개의 문자열로 합친다.
한 개로 합친 문자열을 다시 정규 표현식을 이용하여 단어 단위로 자르게 된다. 찾고자 하는 정규식은 '\b\w+\b'로, 이는 1글자 이상의 단어 구분을 위해 사용된다. 또한 대소문자로 인해 중복을 처리할 수 없게되는 상황을 막기 위해 모든 글자를 소문자로 변환한다. 이렇게 단어 단위로 자른 변수를 불용어 처리 함수로 넘겨준다.

미리 단어로 취급하지 않을 문자열들을 리스트로 만들어 놓고, 해당 리스트와 넘겨 받는 리스트를 비교하여 만약 불용어 리스트에 존재하는 단어라면 제외시켜주는 함수이다.

collections 라이브러리의 Counter 함수를 사용하여 단어들의 개수를 센 뒤 튜플 형식으로 포함되어 있는 리스트 word_freq에 할당하게 된다. 각 단어들 별로 빈도를 나타낸다.

지난 게시물에서 배운 대로 그래프를 그렸다 하지만 여기서 바뀐 점은 x축에 위치한 label들이 45도 기울어진 것을 확인할 수 있다. 이는 막대그래프의 단어가 길어졌을 때 문자열끼리 겹치는 것을 방지할 수 있다.
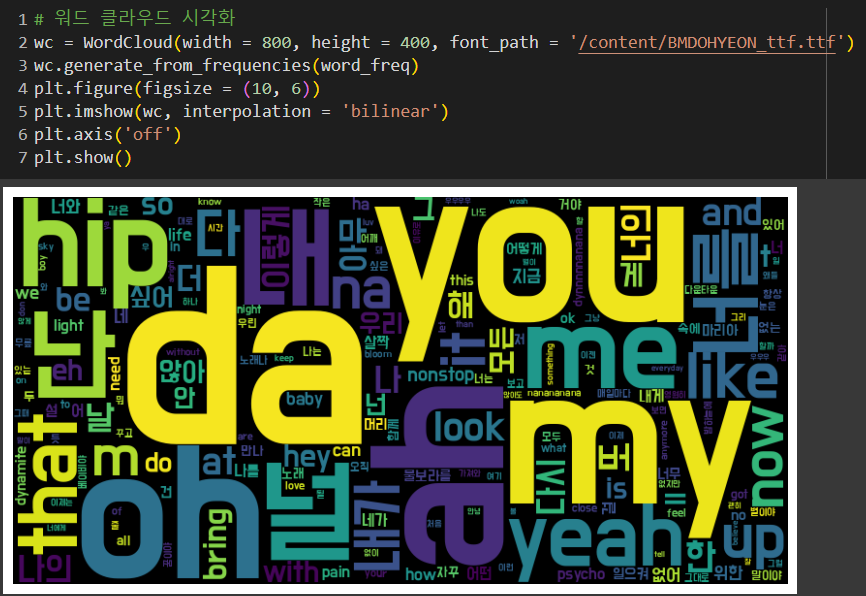
단어의 사용 빈도에 따라 단어 구름들을 만들어보았다.
이렇게 데이터 분석 3일차가 지났다.
프로젝트를 진행할 수 있게 과제를 계속 던져주셔서
내가 뭘 알고 뭘 모르는지 알 수 있는 것 같다. 발표는 덤..
'ABC부트캠프 데이터 탐험가 과정' 카테고리의 다른 글
| [16일차] ABC 부트캠프 데이터 분석 프로젝트 발표회 (0) | 2024.07.28 |
|---|---|
| [15일차] ABC 부트캠프 이미지 크롤링 및 프로젝트 주제 선정 (0) | 2024.07.24 |
| [13일차] ABC 부트캠프 동적 크롤링 및 시각화 (1) | 2024.07.23 |
| [12일차] ABC 부트캠프 ESG Day(데이터로 보는 분야) (2) | 2024.07.20 |
| [11일차] ABC 부트캠프 파이썬을 이용한 데이터 크롤링 1 (2) | 2024.07.18 |